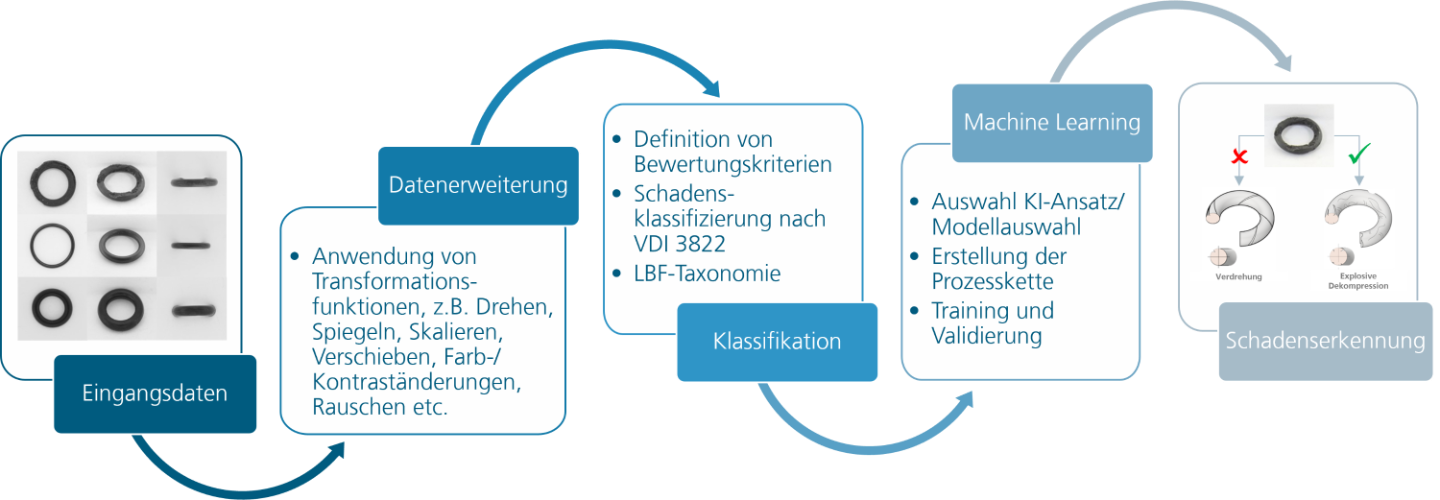
Identifikation von Schäden durch multidisziplinär entwickeltes Assistenzsystem

Durch die vielfältigen Schadensbilder an Elastomerbauteilen ist eine Rückführung auf die Schadensursache nicht immer leicht. Das Fraunhofer-interne Projekt »KI-basierte Schadensanalyse von technischen Elastomeren – KISTE« erörtert die Möglichkeiten, Schadensfälle anhand von künstlicher Intelligenz objektiv zu bewerten. Der entstehende Prozess am Beispiel einfacher Bauteile ist auf kundenspezifische Anwendungen übertragbar.
Elastomere sind extrem hohen und komplexen Anforderungen, wie mechanischen und thermischen Belastungen und unterschiedlichen Medieneinflüssen, ausgesetzt. Schäden an diesen Bauteilen können sowohl aus diesen Belastungen als auch aus Alterung, Abweichungen im Fertigungsprozess und anderen Faktoren resultieren. Eine Analyse von Schäden der Bauteile kann mit Hilfe der VDI 3822 erfolgen. Erfahrung und Fachkompetenz sowie ähnliche Schadensbilder bei unterschiedlichen Schadensursachen führen in diesem Prozess jedoch zu einer subjektiven Schadensbeurteilung. Im Projekt KISTE werden dieser zeit- und kostenintensiven Prozess automatisiert und objektiviert sowie die erforderlichen Rahmenbedingungen (z. B. Inputparameter, Trainingsdatenbasis, Extrapolationspotential usw.) für eine praxisrelevante Umsetzung ausgelotet.
In der ersten Stufe zur objektiven Bewertung der Schadensursachen von Elastomeren in einer Prozesskette lag der Schwerpunkt zunächst auf Untersuchungen zur erforderlichen Datenbasis. Da typischerweise Schadteile nicht in ausreichender Anzahl für das Training eines KI-Modells vorliegen, wurden synthetisch generierte Schadensdaten erzeugt und verschiedene Data Augmentation Methoden wie geometrische Transformationen, Farbänderungen etc. hinsichtlich Wirksamkeit untersucht und angewendet. Auf diese Weise lassen sich eine repräsentative Anzahl an Schadensbildern für unterschiedliche Schadensursachen erstellen, die Prozessanforderungen systematisch ausloten und die Robustheit des Modellansatzes erhöhen.
In einem zweiten Schritt erfolgte die Erweiterung der Prozesskette von einem zunächst rein auf Bilddaten basierenden Klassifikationsmodell zu einem mehrstufigen, multimodalen Klassifikationsmodell. Dazu wurden zusätzliche skalare Inputparameter (beispielsweise Materialkennwerte) ergänzt, um die Genauigkeit der Schadensbestimmung zu erhöhen und den Klassifikationsprozess insgesamt robuster zu gestalten. Weitere Forschungsfragen befassen sich mit der Extrapolierbarkeit der Prozesskette auf Schadensbeispiele abseits des Trainingsdatensatzes der ML-Modelle und der Integration von Methoden der erklärbaren KI zur Optimierung für zukünftige Folgeprojekte.